What is GitOps and how it solve Configuration Drift problem in Kubernetes??

Today containerization has became a standard way to run applications in dev, stage and productions environments and with that container orchestration has became the integral part of deployment process. Containers runs the application and all its dependencies in a isolated instance, kind of VM but much more condensed. They share the OS kernel storage and networking from the hosts that they run on. Containers can move through continuous integration and continuous deployment pipelines in a manner that keeps the OS, the dependencies, and the application unchanged through that entire process. Docker is the most popular container runtime though there are many others.
Now when we have multiple containers running together then we need orchestration. We can many containers on single docker servers or few docker servers, but it will become very complex to manage all of those, manage the networking, manage the storage, manage the orchestration of those containers, and that’s where Kubernetes (K8s) comes into play. Kubernetes is an orchestration solution, and what it does is it really abstracts away the complexity of running multiple or many containers, and even running those across many clusters. It combines the compute, the network, and storage for hundreds and thousands of containers because they rely on those components, that underlying infrastructure. And it gives you a way to become declarative in regards to our management and how we approach that.
High Level Understanding of CI/CD process
This is the high level understanding of containerization and K8s, since this article is not about Containers and Kubernetes so we will not get into the depth of them. Now before jumping into the core concept of GitOps lets first understand how containers and Kubernetes fits into CI/ CD pipelines.

Above diagram shows a standard continuous integration and delivery process. This process can be quite complex but for our understanding lets try to keep it simple.
- Here first a developer commit and push the code to a version control system (generally git)
- Create a pull request to merge into main branch. Once the code is merged it triggers the automated build which incorporates these committed changes.
- The build occurs on a CI server and if all goes well with the build and tests, a container image for the application is built and pushed to a container registry. This process is known as continuous integration.
- Container images that represent different versions of the application are stored in the registry for deployment on various staging environments for testing. As an extension to continuous integration, these steps are termed continuous delivery.
- When it’s deemed appropriate, an automated production deployment of a new version of the application can be triggered.
There could be multiple manual steps involved in CI/ CD process, but when a process that has been developed over time reaches a level of maturity, it might be possible to remove the manual interventions. This is called as continuous deployment.
During the continuous delivery process K8s is instructed to create the desired state and then individual containers get created from the image. But container images are immutable in nature, so when we need to update our deployed application, we need to create a new container image with a new code and all dependencies. In order to bring the desired state k8s pull the image from remote registry and to express the desired state of Kubernetes, we need to provide it with a set of Kubernetes configuration manifests that describe how our application is going to run. Those manifests refer the container image to identify which version of the application is deployed. These YAML manifest contains other configuration such as number of replica instances, health probes, security and scaling aspects.
Configuration Drift Problem
Kubernetes will attempt to bring about the desired state expressed in these YAML definitions, but it will also respond to subsequent user requests to alter the desired state, and this can be done using imperative commands (kubectl commands) which don’t rely on YAML manifests. Now these imperative commands, result in altering the desired state and the configuration start to drift from what was already defined in YAML manifest.
Let’s try to understand it with an example:
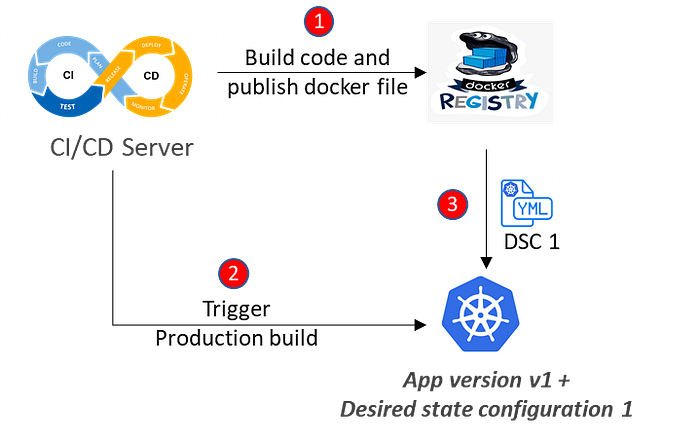
I have simplified the CI/ CD process to focus on how configuration drift problem occur over the period of time. Let’s say to start with we deploy our application to a Kubernetes cluster as app version v1. The automated CI/CD process that we’ve defined is used to apply this configuration to the cluster as our intended desired state (DSC 1).
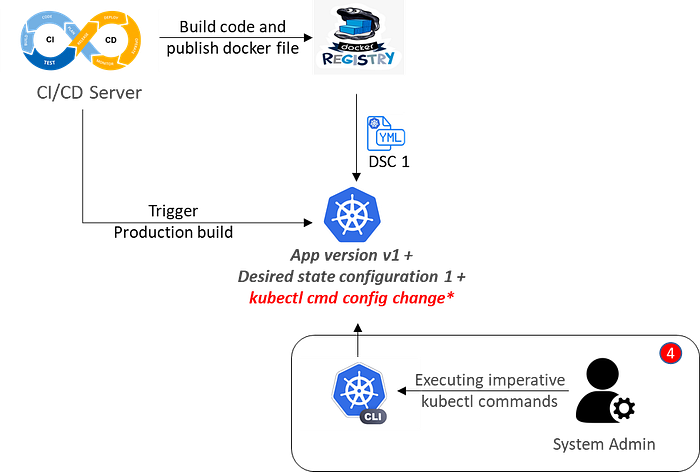
Now the application runs in the cluster for quite some time with defined desired state (DSC 1), but eventually some operational problems occurs such as, due to sudden increase in traffic to the application number of nodes need to be scaled out or some security configuration need to be immediately applied top the cluster and to solve it support team makes some changes regularly on the fly using imperative commands which results in altering the configuration of deployed application (as shown in below diagram).
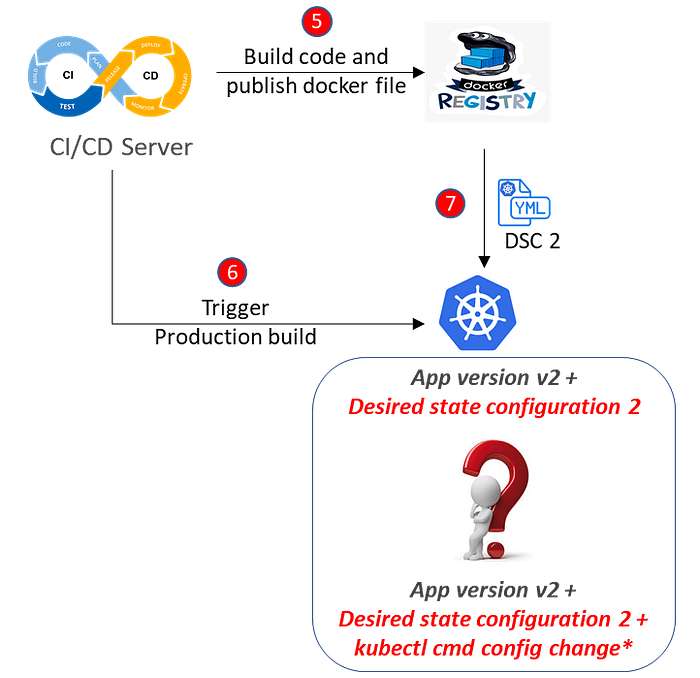
Eventually, after running application in production for long period of time, version 2 of the application (App version 2) is ready with new features, and the workload manifest is uploaded to reference the newer image. Again, our CI/CD process will take care of applying the updated YAML manifest, and we will rely on Kubernetes to gracefully handle the change in desired state. But what is the desired state? Is it the updated manifest referencing the new container image? Is it an amalgamation of the imperative changes we made in cluster on the fly, and the new workload manifest? Who has the overall picture? What does Kubernetes think the desired state should be? The answer to the question is probably nobody knows what the configuration should be. Kubernetes will merge configuration changes as requested, but the state of the cluster will no longer be accurately reflected in the YAML manifests we started out with.
What is GitOps??
Configuration drift can be a serious problem and it’s better that we manage the integrity of the configuration so that what is configured in Kubernetes accurately reflects the expectations. To solve this problem GitOps is one such approach which can be used to effectively manage the configuration and helps to achieve reliable and automated deployments.
GitOps is an operating model pattern for cloud native applications that relies on software automation to establish a desired state, which has been expressed declaratively in a version control system (Infrastructure as a code in Git) and it makes version control system as source of truth which provides the automated continuous delivery.
Lets further elaborate the definition. So GitOps is generally describing the desired state configuration and store it in version control system such as git which manage the change in the desired state. Then this desired state is applied to the target environment (kubernetes but not necessarily ) through automated agents (such as Flux or Argo CD) and then the actual state of the system is continuously monitored against what is available in version control system. The automated agents can be external or run within the system itself. They continuously monitor the system and and act of configuration drift is observed. As an action it can be configured to raise an alert or it can make the fix in an automated fashion.
Deployment Strategy for GitOps
Deployment strategy for GitOps can be implemented in either push model or pull model, lets try to understand both of them.
Push Model
In the beginning of the article we have discussed how standard CI/ CD process look like where developer pushes the code to VCS and then through pull request a CI build is triggered. From there docker file is produced as a result of CI process which is stored in a registry and deployed to K8 cluster during CD process as shown in steps 1,3,4,5 and 6 below.
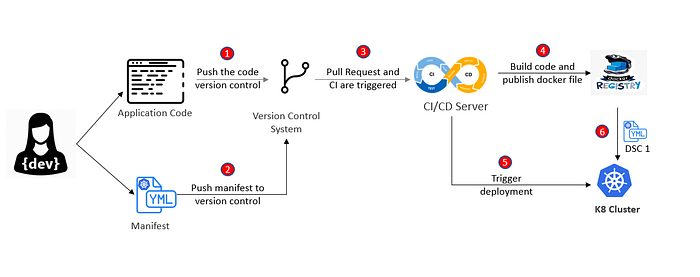
Push deployment strategy for GitOps look quite similar to the CI/ CD process except in case manifest file which contains the configuration that defines the objects K8 server need to create. Manifest file is also managed in VCS which can be the same VCS or separate repository. We treat the manifest in the same way as we treat application code. As we have discussed above the automation process to deploy the application and monitor it can be external or exists with in the system itself, in case of push deployment strategy it is external to the system and generally managed by same CI server. CI server can execute “kubectl apply…” command and manifest is applied to the cluster.
Pull Model
. In a GitOps pull scenario, instead of the automation operating from outside the cluster, an agent is deployed inside the cluster. It runs as a Kubernetes operator and is able to track the VCS repo that contains the Kubernetes manifests.
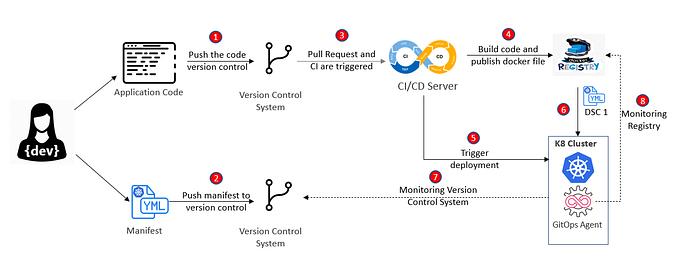
As it runs inside the cluster, it’s also aware of the actual state of the cluster. If it detects a difference between the source of truth contained within the VCS and the actual state within the cluster, it takes action. It either alerts or attempts to reconcile the differences by syncing with the content of the VCS. It is also possible to configure the agent to monitor the remote container registry for new versions of the application code in the form of a new image. The agent is then able to update the manifests in the VCS, which triggers a new automated deployment based on the new container image.
Since the pull deployment strategy requires a K8s operator to execute its action we need to look for specific tooling for that. Though there are multiple tools are available but 2 of them are most popular and recommended by CNCF as well. i.e. Flux and ArgoCD. We can get more details on these tools on their respective websites.
This article was about understanding of GitOps and how it resolve configuration drift problem to implement high level of governance in the system. Next we will deep dive into the GitOps tools and see how practically they are implemented….
[Disclaimer: This is a personal blog. Any views or opinions represented in this blog are personal and belong solely to the blog owner and do not represent those of people, institutions or organizations that the owner may or may not be associated with in professional or personal capacity, unless explicitly stated.]
